



Mégis milyen kapitalizmus az, ami leépíti a fogyasztói társadalmat és tálcán kínálja az egyén preferenciáját a techno feudalista földesuraknak?
A nyár elején egy baráti körben töltött hétvégén merült fel a kérdés ama bizonyos közelgő recesszióról. A kérdés apropóját az adta, hogy bár mindenki látja és érzi az inflációt, illetve azt is el tudja mindenki képzelni, hogy milyen világ vár ránk, ha például megszűnnek az ársapkák… De az elmúlt 12 év konjunktúrája csak nem tűnhet el egy pillanat alatt és nem kerülhet mindenki mélyszegénységbe.
A beszélgetés során felvázoltam a társaságnak egy víziót, amit egyrészt kétkedés fogadott, másrészt viszont némi kellemetlen feszengés, hiszen a vízióm jelei már akkor is láthatók voltak.
A vízió végtelenül egyszerű: a termékek és szolgáltatások nélküli fogyasztói társadalom.
Azóta eltelt bő két hónap és nap mint nap egyre nyilvánvalóbb ezen vízió leképződése. Szinte naponta kapok olyan feedbackeket, hogy itt is, ott is bezárt egy vállalkozás mert nem bírják az energiaárak alakulását. A legtöbb családi vállalkozás már évek óta világpiaci áron veszi az áramot és akár még idén első negyedévig is tudtak igen kedvező éves szerződéseket kötni az MVM-mel. Ezek a szerződések nagy része az idei tél közepén fog lejárni. Azon vállalkozások, akik ma (konkrét példa következik) kötik újra az éves áram szerződésüket, azok egészen pontosan kilencszeres áron kapják az áramot további egy évre a megelőző időszakhoz képest. Ehhez jön még hozzá, hogy néhány hete a 3 tonnánál kisebb céges autókra is megszűnt a benzinár sapka, illetve most fogják megkapni az első rezsiszámlájukat azon magánszemélyek is, akik már lassan egy hónapja rettegnek attól a pillanattól, amikor kezükbe veszik a négyszer-ötször nagyobb gázszámlájukat és a közel kétszeresére növekedett villanyszámlájukat. Ezen munkavállalók számára nem nagyon lesz más kiút, mint a fizetésemelés kérése. Ezen terhek pillanatok alatt írják nullára, vagy akár veszteségbe a legtöbb szolgáltatói vagy fogyasztási termék előállító iparágat. Márpedig ez a tendencia egyáltalán nem hazai specifikus.
Ezen tendencia hatására drasztikusan csökken a kínálat és az alternatív termékek/szolgáltatások száma; ami logikusan újabb kormányzati beavatkozásokat fog szükségessé tenni. Különösen akkor, ha a további ársapkák esetén kényszerül a kormány a jogosultak körének csökkentésére.
Etéren a személyes jövőképem igen borús, különösen azért, mert egyre inkább visszaigazolódik az eredeti tézisem. Az elmúlt bő 12 év konjunktúrája, az ingyen hitelek, az ágazati helikopterpénz szórás és persze a családtámogatási fókusz lényegében komplett iparágakat formált át és tett függővé a könnyen hozzáférhető forrás irányába. Ezen cégek nagy része valójában működésképtelen azon transzferek nélkül, amik most pillanatok alatt hullanak ki alóluk a recesszió okán. Az előttünk álló évek média fókuszában bizonyosan komoly szerepet fognak kapni a “látvány nagyvállalatok” szanálása körüli botrányok; míg személyes életterünkben folyamatosan fogunk találkozni azzal, hogy jól megszokott bevásárló és/vagy szórakozó helyei fognak sorra bezárni.
A vízióm egy olyan recessziós időszak, ahogy pénzünk ugyan lehet, hogy lesz… de nem lesz egyszerű elkölteni, mivel nem lesz sem termék, sem szolgáltatás. Talán érdemes most időt szánni arra, hogy mindenki elbeszélgessen a nagyszülőkkel és feltegyen nekik olyan kérdéseket mint pl, hogy milyen is volt az élet a KGST-ben, hogy is nézett ki egy autó rendelése és leszállítása a MERKURnál, milyen is volt a kínálat a KERAVILL-ban… hiszen ők vagy szüleik élhettek már hasonló gazdasági környezetben, mint ami a jelek szerint előttük áll.
Szeretnék azonban megnyugtatni mindenkit még mielőtt bárki is azzal vádolna, hogy indokolatlanul tekintek vissza a szocializmusba és próbálom azonosítani a jövőt azzal a korszakkal. Szó sincs erről. Bő harminc évnyi “kapitalizmus” biztosan nem fog nyomok nélkül maradni a társadalmunk szövetében. A globális kapitalizmus kitermelte számunkra a sérthetetlen technokrata szupervállalatokat, akik boldogan fognak szolgálni bennünket és persze élni belőlünk… pénzünkből, adatainkból és az általuk alakított véleményünkből/preferenciáinkból. Márpedig ezen szereplők térnyerése még koránt sem ért véget.
2016-ban még az egész világ a Facebook – Cambridge Analytica botrányától volt hangos, illetve attól, hogy adatelemzéssel és preferencia befolyásolással milyen szinten tudták alakítani a Brexit referendumot. Azóta azonban a legtöbb fejlett demokrácia már átesett egy-két olyan választáson, ahol teljesen természetesnek éltük meg, hogy hasonló módszerekkel próbálták befolyásolni a döntések kimenetelét. Mára végtelenül divatos “privacy focus”-nak nevezni azt, amikor egy technológiai vállalat adatot gyűjt rólunk és felhasználja azt akár velünk szemben is. Köszönhetően az EU GDPR szabályozásnak mára teljesen triviális mindenki számára, hogy egyszerűen meg sem tekinthetünk egy weboldalt anélkül, hogy tevőlegesen hozzájárulnánk minden adatunk szabad felhasználásához. A magánélet védelme az online térben okafogyottá vált, pont úgy, ahogy az individuum is. Mi mindannyian tömeg vagyunk, mely vélemény és preferencia formálása az egyik legnagyobb üzletté vált.
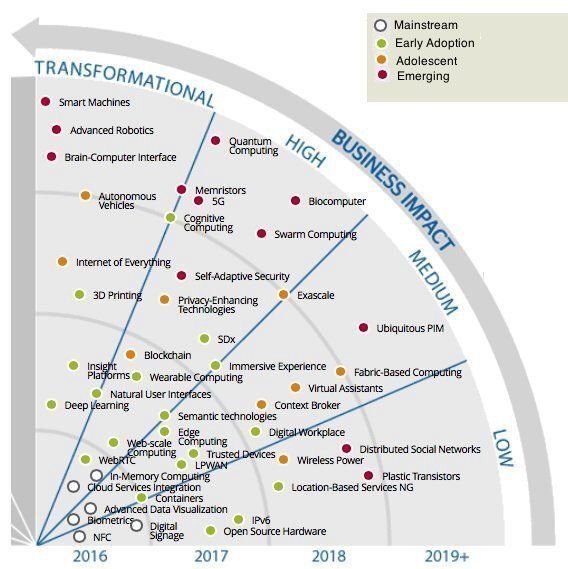
Talán soha sem volt annyira bizonytalan az emberiség jövőképe, mint ma, ha középtávon szeretnénk előre jósolni. Azt bizonyosan már belátta az olvasók nagyobb része, hogy a “fogyasztói társadalom” eszméje leáldozóban van. És bár ezen okok miatt tűnhet felelőtlenségnek új társadalmi modellekkel riogatni az olvasót; én azonban mégis veszem magamnak a bátorságot, hogy legalább címszóban megtegyem ezt: “techno feudalizmus”. Egyelőre csak annyit kérek, hogy rakja el mindenki ezt a fogalmat magában. Érlelje. Ízlelgesse. Barátkozzon vele…
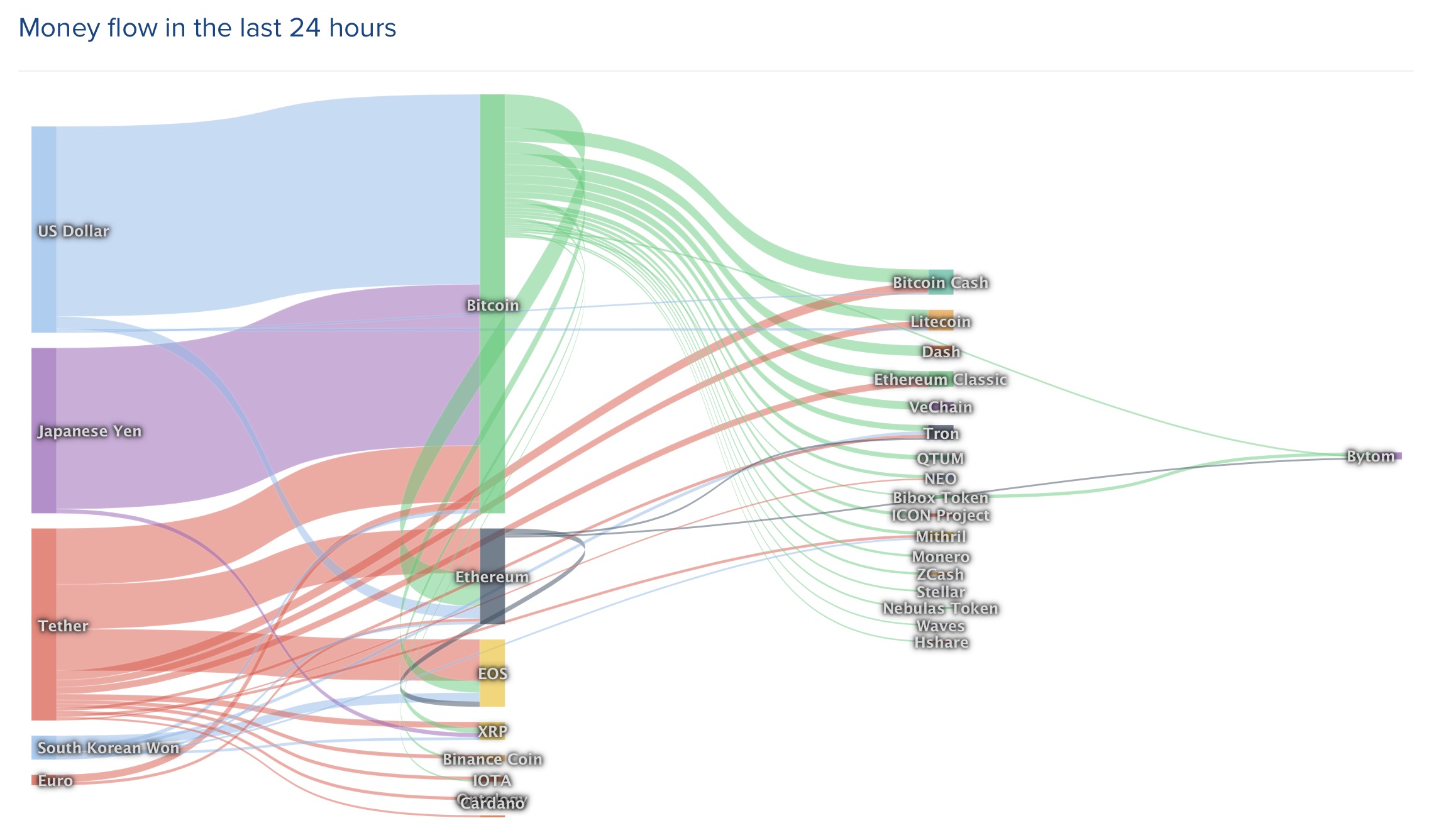
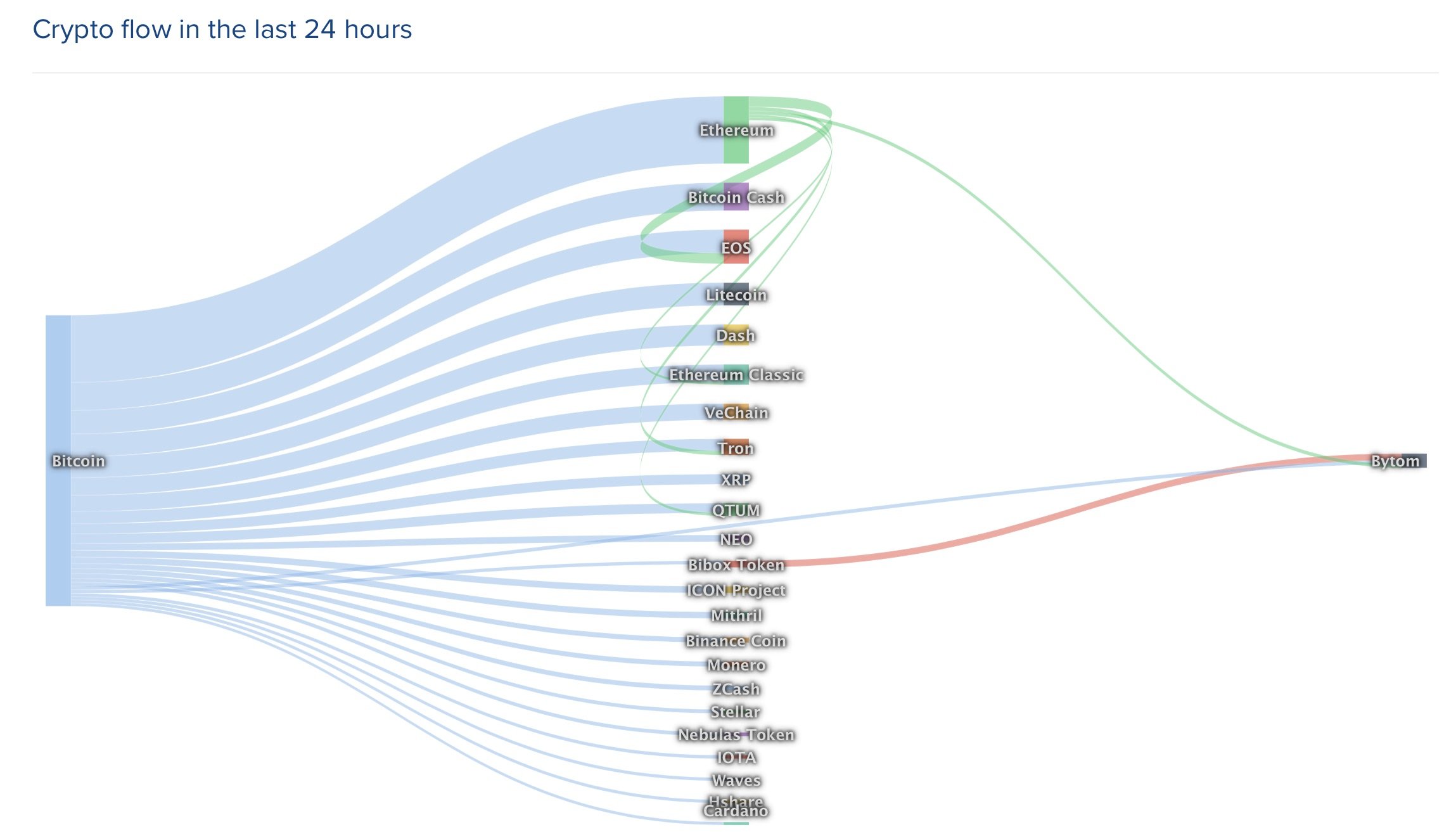

 Sokszor hallottam, olvastam már, hogy a Machine Learning (ML), magyarul: Gépi tanulás, lényegében egy olyan szintje az informatikának és az adatelemzésnek, amely már sokkal inkább tudományos tapasztalatokat igényel, mintsem programozói ismereteket. Sok esetben valamiféle mesterséges intelligenciának tekintik a ML-t (nem alaptalanul), amely abból a szempontból igaz is lehet, hogy a hétköznapi életben ismert és használt gépi tanuláson alapuló megoldások (pl. beszédfelismerés, képeken arcfelismerés, stb.) valóban mesterséges intelligenciára és gépi tanulásra épülne. Ettől függetlenül a gépi tanulás egyébként közel sem annyira nagy ördöngösség ami miatt tudományos fokozat kellene a megértéséhez és használatához.
Sokszor hallottam, olvastam már, hogy a Machine Learning (ML), magyarul: Gépi tanulás, lényegében egy olyan szintje az informatikának és az adatelemzésnek, amely már sokkal inkább tudományos tapasztalatokat igényel, mintsem programozói ismereteket. Sok esetben valamiféle mesterséges intelligenciának tekintik a ML-t (nem alaptalanul), amely abból a szempontból igaz is lehet, hogy a hétköznapi életben ismert és használt gépi tanuláson alapuló megoldások (pl. beszédfelismerés, képeken arcfelismerés, stb.) valóban mesterséges intelligenciára és gépi tanulásra épülne. Ettől függetlenül a gépi tanulás egyébként közel sem annyira nagy ördöngösség ami miatt tudományos fokozat kellene a megértéséhez és használatához.