



Ez a cikk egy több fejezetes gépi tanulásról szóló cikksorozat második fejezet. A jelenleg elérhető fejezetek:
Miután az alapokkal megismerkedtünk ideje belecsapni a lecsóba. A Machine Learning (ML) egyik leggyakrabban használt és legszélesebb körben ismert interpretációja a regresszió és annak alternatívái közül is a lineáris regresszió. Sokan ezen szó hallatán gyomorgörcsöt kaphatnak és rémálomként idézhetik fel az egyetemi mat/gazd. stat. élményeiket. Igen, ez ugyanaz a regresszió, amiről ott is tanultatok.
Azon olvasóknak akiknek vagy már megkopott ez a tudása, vagy nem is tűnik számukra ismerősnek ez, azoknak egy kis gyorstalpaló:
Az egyszerű lineáris regressziót leggyakrabban olyan esetekben láthatjuk, amikor valamilyen adatoknál (pl. árfolyamgörbék, teljesítménymutatók) megjelenik egy trendvonal. A tendvonal a lineáris regresszió eredménye. A lináris regresszió során azzal a feltételezéssel élünk, hogy két vagy több adat között van olyan összefüggés, hogy az egyik adathalmaz értékét megszorozva egy konstans értékkel (B1), majd hozzáadva egy másik konstans értéket (B0) megkapjuk a másik adathalmaz (függő adat) értékét. Az egyszerű lineáris regresszió esetén ennek képlete:
Nem nagyon beletúrva a szigurú elméletbe, amit egyébként a wikipédián bárhol megtalálhatsz, az egyszerű lineáris regresszió célja, hogy az függő és független adatok által felrajzolt ábrára tudj húzni egy olyan (trend) vonalat, amely trendvonalra igaz, hogy bármely X tengelyen ábrázolt (független) érték esetén a tendvonal által felvett érték és az Y tengelyen ábrázolt függő érték közötti különbség négyzete a minimumhoz tart. Szóval az összes berajzolható trendvonal estén igaz, hogy a regresszió során keletkező trend vonal esetén a legkisebb az eltérés a vonal és a valós ábrázolt pontok között.

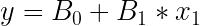
Mivel az előző szakasszal minden bizonnyal elvesztettem az olvasó érdeklődésének nagy részét, ezért megpróbálnám egy élő példával visszanyerni azt:
- Vegyük azt, hogy adott több száz iskola, amiben tanul több ezer diák. Ezek a diákok ugyanarra a vizsgára tanulnak. A tananyag online érhető el és az e-learning rendszer rögzíti, hogy melyik diák mennyi időt szentelt a tanulásra.
- Ezt követően lezajlik a vizsga és a kiértékelés, mely során a diákok százalékos eredményt kapnak.
- Rendelkezésünkre áll két adat, nevezetesen: elért eredmény és a felkészülésre szánt idő. Érdemes lehetne vizsgálni, hogy vajon a kettő között van-e összefüggés. Tehát időarányosan a tanulással töltött idő vajon arányosan kihat-e a kapott eredményre.
Az ilyen jellegű elemzéseknek a tökéletes eszköze a lineáris regresszió. Hiszen az eredményt függő adatként használva (y tengely), a tanulásra fordított időt pedig függetlenként használva (x tengely) máris fel lehet vázolni az eredményt és lineáris regresszióval megrajzolható a trendvonala. A konkrét trendvonal egyébként ebben a konkrét esetben elég komoly szórást fog mutatni, amiből jogosan le lehet vonni a következtetést, hogy a két adat (eredmény és tanulási idő) elég lazán kapcsolódik csak. Azonban az adatsort kiegészítve további statisztikai adatokkal (pl. korábbi eredmények, életkor, felvételi pontszáma, hiányzások száma, betegségek száma, stb.) egyre inkább pontosítható a regresszió, ami ha kellőképpen pontossá válik, akkor akár az a helyzet is előállhat, hogy az előtt megmondható közel pontosan egy adott diák eredménye, hogy kezébe vette volna a vizsgalapot. Ezt a folyamatot nevezik predikciónak. A gépi tanulás predikciós ágának egyik leggyakrabban használt algoritmusa a regresszió. Amikor két változó közötti kapcsolatot kívánjuk felkutatni, akkor beszélünk egyszerű lineáris regresszióról, amikor viszont egy függő értékre ható több független érték kapcsolatáról akkor pedig többszörös lineáris regresszióról. Ennél a két modellnél persze lényegesen több interpretációja létezik a regressziónak (SVA, decision tree, stb.), de jelen cikk keretei között maradjunk csak ennél a két esetnél.
[commercial_break]Bár az egyszerű lineáris regressziónál is előfordulhat, de leginkább a többszörös lineáris regressziónál fordul elő, hogy az egyszeri statisztikus belecsúszik a változó kategorizálásból keletkező dummy változók csapdájába. Ez ugye akkor keletkezik, ha egy változó nem valamilyen számszerű értéket tartalmaz, hanem egy felsorolást, amit dummy változókba szervezve rakunk a regresszió számára előkészített datasetbe. A ‘dummy variable trap’ néven elhíresült tipikus ML hiba elkerüléséhez annyira van csak szükség, hogy az egy közös kategorizálandó változóból generált dummy változók közül mindig eggyel kevesebbet kell berakni a képletbe, mint amennyi az összes opció. Ezzel a módszerrel biztosítható, hogy a regresszió minden lehetséges kategorizálandó változót azonos súlyban alkalmazzon az algoritmus.
Mielőtt nagyon belemélyednénk a regresszióba tisztázzunk még egy fontos kifejezést, ami szintén ismerős lehet a felsőoktatási tanulmányokból: “statisztikailag szignifikáns”. A regresszió során az a célunk, hogy adatok között kapcsolatot feltételezzünk. Két adat között egy sok esetben logikai úton is megállapítható, lásd a fenti példánál logikusan következhet, hogy a tanulás mennyisége arányos az elért eredménnyel. Ezért a regressziós modellünk minden bizonnyal statisztikailag szignifikáns lehet. Azonban ha számos további független adatot is bevonunk, akkor bizony érdemes az egyes adatokat hatását vizsgálni a modell szempontjából, tehát hogy a kérdéses változó szignifikáns-e a modell szempontjából. A kosábbi példában már említettem néhány lehetséges többlet változót, mint pl: “korábbi eredmények, életkor, felvételi pontszáma, hiányzások száma, betegségek száma“. Ezekről “szabad szemmel” már lényegesen nehezebb eldönteni, hogy statisztikailag szignifikánsak avagy sem. Az életkor tipikusan jó kérdés lehet, hiszen a vizsgát nagy bizonyossággal azonos életkorúak töltik ki, ezért a +/- 1 életév nem biztos, hogy releváns. A lehetséges bevonandó független változóket éppen ezért a modell kialakítása során érdemes értékelni és érdemes meghatározni, hogy milyen mértékben várjuk el a modellben szereplő független változók szignifikánsságát a függő változóra. A releváns változók meghatározására számos módszer található, ezek közül egy konkrét példa:
- Kizárásos módszer (Backward elimination): Legeneráljuk az összes lehetséges független változóval a modellt, majd kiszűrjük belőle a leggyengébb szignifikánsságú elemet, majd újra generáljuk a modell-t. Addig ismételjük folyamatosan a leggyengébben ható elem kizárását, amíg elérjük a meghatározott szignifikánssági küszöbértéket. A lineáris regressziós modell során hozzáférhetővé válnak az egyes független változók hatása a regresszióra. Ezek a paraméterek között többek között ott van a P érték (probability, valószínűség), amely kapcsán ugye ismeretes, hogy a P érték minél alacsonyabb annál szignifikánsabb a kapcsolat az adott független és függő változó között. Tehát minden iterációban a legmagasabb P értékű paramétert kell kizárni. Akkor érdemes megállni, ha a modellben szereplő összes független változó P értéke alacsonyabb a meghatározott szignifikánssági küszöbnél. Ennek meghatározására persze nagyon sok jó modszer van, de ökölszabályként ez az érték valahol 5 és 10% (0.05 és 0.1 között) szokott kijönni. Ha a regressziós modellel az a célunk, hogy minél pontosabb predikciókat tudjon adni, akkor érdemes nagyon alacsony szignifikánssági küszöböt meghatározni. Ennek persze csak akkor van értelme, ha egyrészt nagyon sok lehetséges független paraméterünk van, másrészt pedig jogosan feltételezhetjük, hogy ezek egy része valóban jelentős hatással van a függő változóra.
A fentebb leírtakkal nyilván csak a regresszió jéghegyének csúcsát kapargattuk. Bár a regresszió kapcsán fontosnak tartottam kifejteni a módszer mögötti hátteret, de úgy összességében nem célom a cikksorozattal túlságosan beleásni a ML algoritmusok hátterébe, ezért a későbbi fejezetekben sokkal inkább szeretnék a gyakorlati példákra és alkalmazhatóságokra koncentrálni, mintsem az algoritmusok statisztikai, logikai hátterére.
Szóval aki, ködösen követi az eddig leírtakat és vakargatja a fejét, hogy merre is tart ez a cikksorozatom, azoknak jó hír, hogy innentől a gyakorlati használhatóságra koncentrálok, akinek pedig mindehhez hiányzik a statisztikai, logikai alap, az amúgy is megtalálja a hiányzó információkat wikipédián. Mindennek szellemében a harmadik fejezetet egy életszerű predikciós példának szeretném szentelni, amin keresztül mutatom be, hogy miként is működik a regresszió és hogyan érdemes jó regressziót modellt választani.
