Olyan jól sikerült az előző körös analyst recruit felhívás, hogy annak sikerét kihasználva szeretnék egy újabb felhívást tenni. Nem tudom megállni, hogy ne tegyek a téma kapcsán azonban egy fricskát: multis/nagybankos vezetőként közel 10 évig szenvedtem a(z) <insert random jobportal>-(va-)/(ve-)l, ahol kulcsfontosságú pozíciókra tudtak hozni negyedév alatt 3-4 egyébként teljesen alkalmatlan jelentkezőt. Ehhez képest a saját tematikus blogomra feldobok a saját stílusomban egy recuritot, amire egyből beesik több mint egy tucat jelentkező, akik nagy része egyébként már túl van a második körön és éppen a shortlist összeállításán ügyködünk. Emlékszem a 2000-es évek első felében volt ilyen a piac, amikor egy IT biztonsági szakértő vagy php fejlesztő pozícióra akár 40-60 ajánlat is érkezett, melyek igen nagy része egyébként teljesen passzolt is az avatarba.
 Szóval ezen fellelkesülve futnék még egy kört: Jelenleg bejáratott frontend programozó csapattagunk üveghangon dolgozik most kb 3-4 projekten, viszont az élet nem áll meg, ezért szeretnénk bővíteni a csapatot. Jelenleg ebben a témában biztosan nem tudunk/akarunk fulltime foglalkoztatni valakit, ezért mindenképp freelancer vagy parttime munkaerőt keresnénk.
Szóval ezen fellelkesülve futnék még egy kört: Jelenleg bejáratott frontend programozó csapattagunk üveghangon dolgozik most kb 3-4 projekten, viszont az élet nem áll meg, ezért szeretnénk bővíteni a csapatot. Jelenleg ebben a témában biztosan nem tudunk/akarunk fulltime foglalkoztatni valakit, ezért mindenképp freelancer vagy parttime munkaerőt keresnénk.
Elvárások: NodeJS/Javascript készségszintű tudás, ajax/async alapú dinamikus tartalom management. Nem kell felületeket és folyamatokat tervezni, ezeket készen kapod, viszont ne okozzon kihívást, ha egy vektorosan lerenderelt felülettervet pixel pontosan kell implementálnod a runtime kódban. RestAPI/WSGI és JSON leíró formátum készség szintű ismerete szintén elvárás.
Mivel kell foglalkozni: Az Inlock meglévő fejlesztései mellett számos egyéb kisebb/nagyobb jellemzően crypto és blockchain orientált projektek fejlesztése.
Ami előnyt jelent: komoly előny, ha pythonban foglalkoztál már WSGI-vel (pl Flask) vagy bármilyen más python alapú API frameworkkel. Az is jó persze, ha bármilyen más környezetben foglalkozál API fejlesztéssel… már persze, ha nem gond, hogy megtanuld ugyanezt python/flask-en is. Szintén nagyon komoly előnyt jelent, ha nem most ezt olvasva hallasz először az ElasticSearchről. Ha mégis így lenne és szeretnél legalább képbe kerülni, akkor: https://variance.hu/?s=ElasticSearch
A projektek, fejlesztések és issuek trackelésére asanát használunk, így könnyedén tudsz akár a világ másik végérők is dolgozni, de persze komoly előnyt jelent, ha heti/két heti rendszerességgel azért el tudsz jönni egy followup meetingre, hogy személyesen is át tudjuk beszélni az progresst.
Szintén előnyt jelent, ha fejből vágod az összes WoW kieg 10+ raid instance főbossának nevét és halványan emlékszel is még esetleg a taktika főbb lépéseire, különösen ugye illidanra és c’thunra. Bár ezen előnynek úgy egyébként nincs semmi köze a konkrét munkához…
Mit kínálunk: blockchain, tokenizáció és kriptopénz alapú projekteken tudsz úgy tanulni, hogy közben a meglévő tudásodat és képességeidet is tudod hasznosítani. A jelenlegi informatika és pénzügyi szakma kreatív egyvelegét, ami a nálunk okosabbak szerint is meg fogja változtatni a világot, ha szerinted ott a helyed a jégtörők között, akkor keresve sem tudnál ennél jobb helyet találni magadnak. Mivel jelenleg freelancer pozícióba keresünk kódert, ezért minden projektnél magad fogod tudni eldönteni, hogy érdekel avagy sem az adott téma annyira, hogy csatlakozz. Persze ettől függetlenül nem zárjuk ki a lehetőséget, hogy záros határidőn belül internalizálnánk ezt a feladatot is.
Ha úgy gondolod, hogy szeretnél velünk dolgozni, akkor mindenek előtt NE küldj CV-t nekünk! Helyette végezd el a tovább után található feladatot, ennek eredményét küld el a blog kapcsolat email címére. Ha tetszik a gondolkodásmódod, akkor felvesszük veled a kapcsolatot… Már persze, ha kapunk az emailben elérhetőséget is.
Folytatás…




 Ez a két technológia lényegében uralja a piacot. Előbbi ugye egy robosztus rendszer, ami modulok és célalkalmazások százait vonultatja fel, az utóbbi pedig leginkább keresésre való, de arra viszont nagyon. A megközelítéssel ugye az a baj, hogy a Big Data mint kifejezés pont annyira egzakt mint mondjuk a “cloud”. Tehát önmagában semmit sem jelent és lényegében bármire lehet használni. A megvalószítás technológiai eszközének kiválasztásához nem árt végig gondolni, hogy mit is akarunk tárolni a big data-ban és mit is akarunk azzal csinálni.
Ez a két technológia lényegében uralja a piacot. Előbbi ugye egy robosztus rendszer, ami modulok és célalkalmazások százait vonultatja fel, az utóbbi pedig leginkább keresésre való, de arra viszont nagyon. A megközelítéssel ugye az a baj, hogy a Big Data mint kifejezés pont annyira egzakt mint mondjuk a “cloud”. Tehát önmagában semmit sem jelent és lényegében bármire lehet használni. A megvalószítás technológiai eszközének kiválasztásához nem árt végig gondolni, hogy mit is akarunk tárolni a big data-ban és mit is akarunk azzal csinálni.
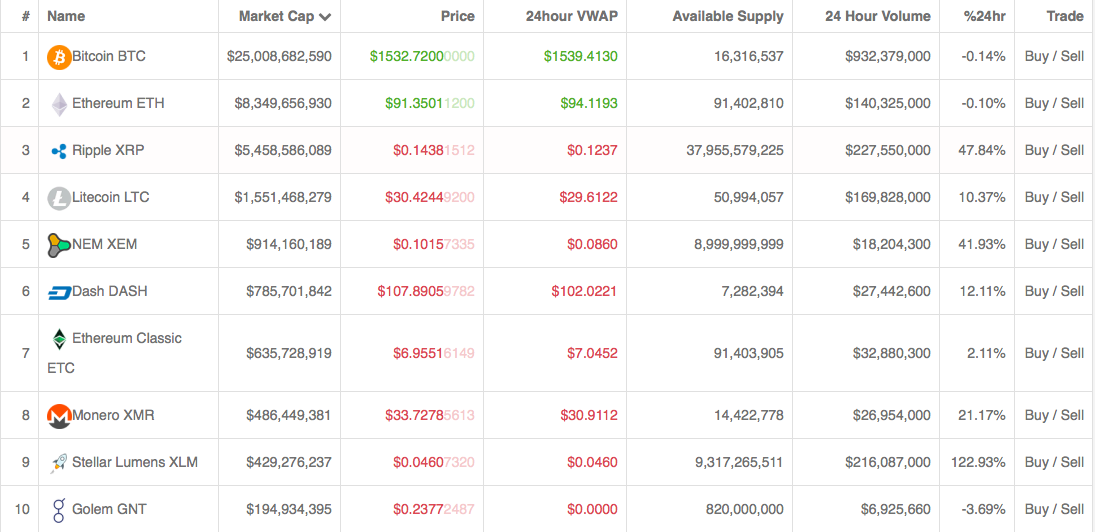 A Zcash témával foglalkozó cikksorozat első részében a bitcoin mellett létező alternatív coinok térhódításáról írtam. Ha érdekel, hogy mik ezek az alternatív coinok és mi milyen módon védettek az ASIC mining ellen, akkor olvasd el ezt a cikket:
A Zcash témával foglalkozó cikksorozat első részében a bitcoin mellett létező alternatív coinok térhódításáról írtam. Ha érdekel, hogy mik ezek az alternatív coinok és mi milyen módon védettek az ASIC mining ellen, akkor olvasd el ezt a cikket: 
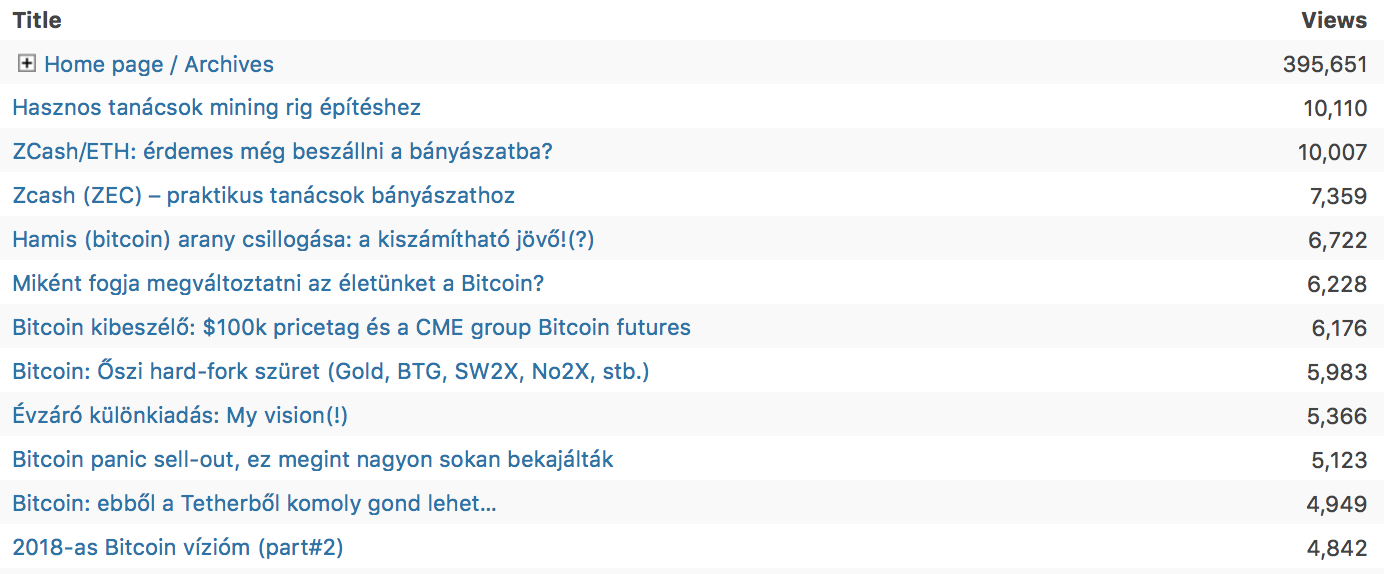
 A tavalyi évben született majd 200 postba 178828 szó került (javarésze természetesen elgépelve…), az idén eddig született 52 postba pedig eddig 45752 szó. (Számomra) érdekes módon a tavalyi és az idei words/post arány is szinte pontosan megegyezik: 880.9 és 879.8
A tavalyi évben született majd 200 postba 178828 szó került (javarésze természetesen elgépelve…), az idén eddig született 52 postba pedig eddig 45752 szó. (Számomra) érdekes módon a tavalyi és az idei words/post arány is szinte pontosan megegyezik: 880.9 és 879.8