Hibátlan lett az OmiseGo tickere: $OMG. Biztosra veszem, hogy nem véletlen az áthallás. Amit az OmiseGo projekt csinál, az finoman szólva is a teljes pénzügyi rendszer megreformálásának az alapja. Személy szerint augusztus közepén figyeltem fel a projektre és legnagyobb bánatomra lekéstem az ICO-t is, így az augusztus 13-i beszállóm óta sajnos ‘csak’ 77,41%-os profitban állok, de azóta is lelkesen pakolom az $OMG-be a pénzemet.
Bő egy hónapja készülök megírni ezt a postot az OmiseGo kapcsán, de szándékosan halogattam eddig. A NEO kapcsán készült cikk a blog eddigi legolvasottabb postja, jól mutatva azt, hogy a hazai crypto közösség is mennyire fogékony az új lehetőségekre. A NEO azonban nem kifejezetten muzsikált jól az elmúlt egy hónapban. Árfolyama mérhetetlen mélységekbe zuhant és bár számomra egy pillanatig sem volt kétséges, hogy tartom a NEO-imat, hiszen hosszútávra vettem, de tudom, hogy sokan kiszálltak belőle jelentős veszteségeket realizálva. Mára kiderült, hogy a NEO történet mögött is csak szándékos… vagy véletlen(?) szerencsétlenségek sokasága állt. Vajon mi kell ahhoz, hogy valaki teljesen hidegen tudjon kezelni egy olyan FUD hadjáratot, mint az e-hét hétfői kínai ICO ban, a Bitcoin Cash indulását megelőző történet, vagy a májusi SEC döntés a Bitcoin ETF-ek kapcsán?
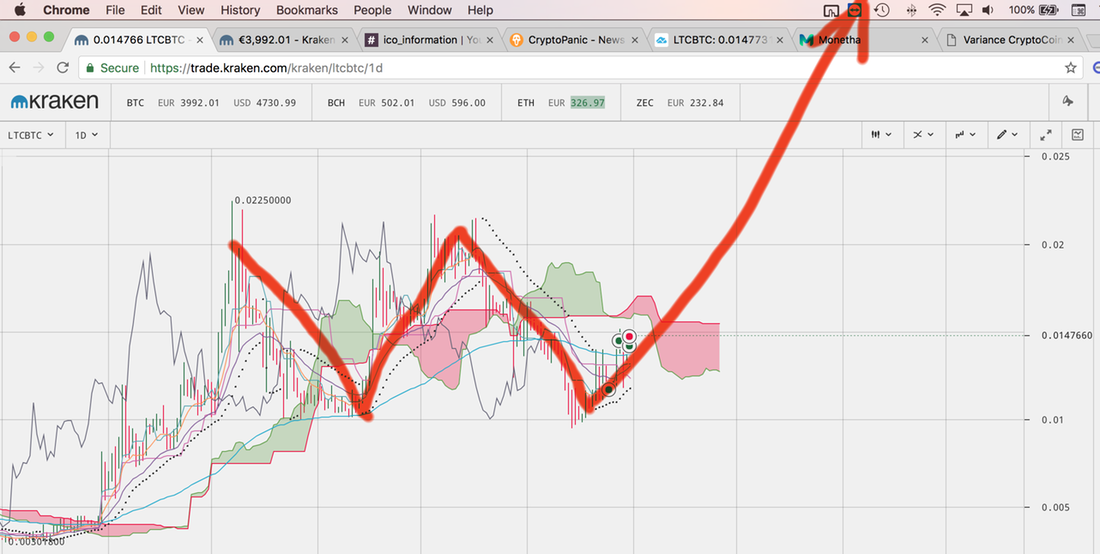
Nehéz ezen történetek mögé nem odaképzelni valamiféle összeesküvés elméletet. Az elmúlt egy hónap történései jelentősen megtépázták a NEO árfolyamát és bár a PBoC (Kínai népbank) ICO regulációs bejelentése a színpadon a Bitcoint tépázta meg, de a háttérben a NEO egy komplex bizalomvesztésen ment át. Majd láss csodát: tegnap előkerült, hogy az ICO kizárás igazából csak temporális és már dolgozzák ki a licenszelési módot, amivel mégis csak lehet honosítani Kínában ICO-kat, amiken ezt követően boldogan részt vehet bármely állampolgár. A hír felröppentével együtt a NEO árfolyama is a sztratoszférába emelkedett, napon belül csinált egy majd 60%-os emelkedést. Persze az öröm nem tartott sokáig, tegnap újabb pletyka látott napvilágot, mely szerint a kínai kormány tömegesen kívánja bezárni a cryptocurrency exchangeket. Nem sokkal később kiderült, hogy a hír nem pont úgy igaz, de ennek ellenére egy zavaros google translate-tel lefordított kínai cikk elég volt ahhoz, hogy újabb tömegek dobják be gondolkodás nélkül a coinjaikat. Majd az árfolyam tegnap este újra zuhant. Ugyanúgy a 4100-as tartományba. Legnagyobb szerencsémre csak a történés első pillanatait kaptam el, amit követően egy 4 órás repülőúton szerencsémre lehetőségem sem volt hülyeséget csinálni… Lehet többet kellene repülnöm 🙂
Így utólagosan kielemezve csak annyit tudok mondani, hogy: minő meglépetés, újra ugyanott volt a resistance, mint két hete. Csak coincidence? Vagy ahogy honosították a fogalmat: csak koincidencia? Ja, hogy nem is magyarosította így senki? Nem baj, akkor én most megteszem. Szóval ez most megint csak totálisan egymástól független történések halmaza, ami valami fura egyveleget ad ki magából?
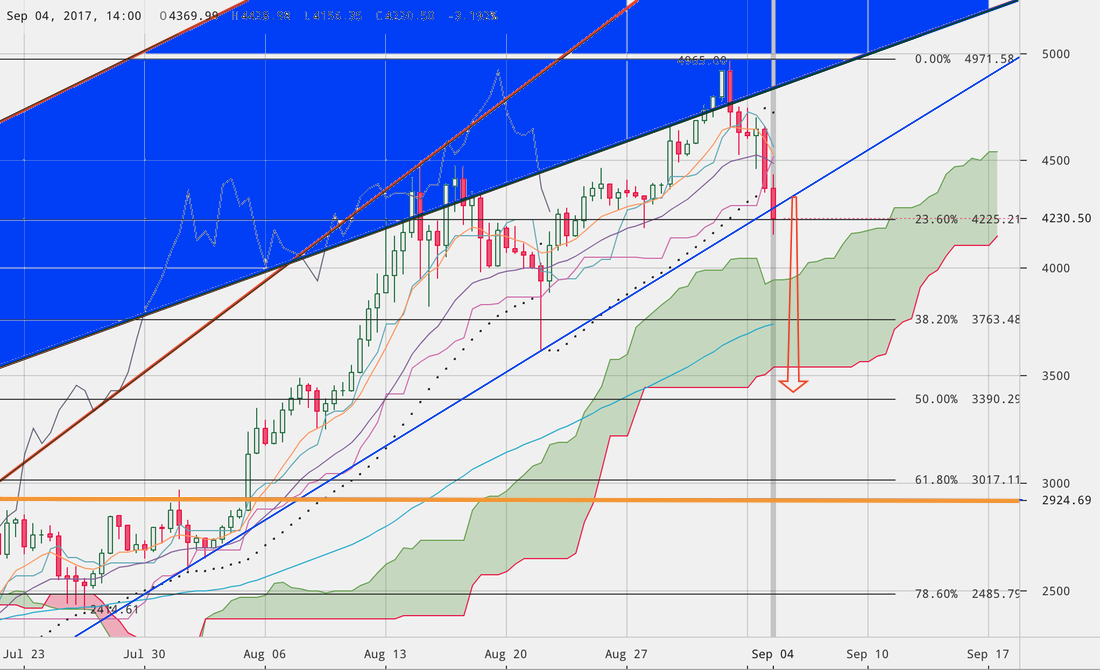 Az árfolyam a kék csatornáról lepattant és az 5000 dolláros ATH-val párhuzamosan rendesen le is fordult, ahogy az nyilván azóta már mindenkinek fel is tűnt. Ami ennél is érdekesebb, hogy a flash crash kapcsán az árfolyam ezeddig minden támaszt áttört és éppen ma kora délután ‘sikeresen’ kitört lefelé a jelenlegi csatornából. Már áttörte a 23,6%-os fibonacci szintet is ezzel kvázi “légüres térbe” került, innentől szabad a pálya bármerre. Nem gondolom komoly támasznak sem a 38.2%-os, sem pedig az 50%-os fibonacci sávokat. Amikor azt mondom, hogy “nem gondolom”, akkor itt nyilván az általam nagy tiszteletben tartott TA-k által publikált információkra alapozott privát véleményemet vetem képernyőre.
Az árfolyam a kék csatornáról lepattant és az 5000 dolláros ATH-val párhuzamosan rendesen le is fordult, ahogy az nyilván azóta már mindenkinek fel is tűnt. Ami ennél is érdekesebb, hogy a flash crash kapcsán az árfolyam ezeddig minden támaszt áttört és éppen ma kora délután ‘sikeresen’ kitört lefelé a jelenlegi csatornából. Már áttörte a 23,6%-os fibonacci szintet is ezzel kvázi “légüres térbe” került, innentől szabad a pálya bármerre. Nem gondolom komoly támasznak sem a 38.2%-os, sem pedig az 50%-os fibonacci sávokat. Amikor azt mondom, hogy “nem gondolom”, akkor itt nyilván az általam nagy tiszteletben tartott TA-k által publikált információkra alapozott privát véleményemet vetem képernyőre.
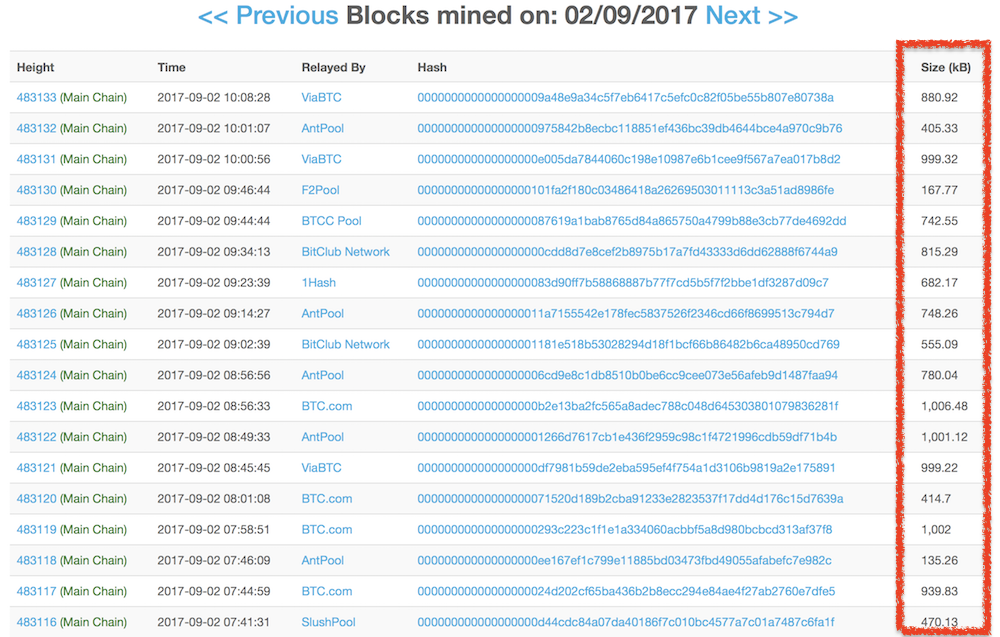
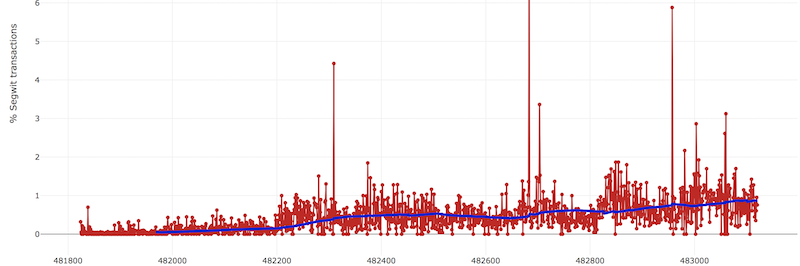
 A GDAX-on néhány perce a Litecoin elérte a 98.3 USD árfolyamot és egyben bekarcolta a 0.02-es BTCLTC keresztet is, ami kétségtelenül annak köszönhető, hogy a Litecoin – mint a BTC produktív teszt környezete – ma bemutatta egy élő lightning network utalással azt, amiről évek óta szól a Bitcoin skálázási vita geek/technológiai oldalának propaganda gépezete. Az időközben “BsCore” gúnynévvel illetett Blocksteam és egyéb Bitcoin Core fejlesztőket tömörítő bagázs az elmúlt cca. egy évét arra tette fel, hogy létrehozza, implementálja és elfogadtassa azt a koncepciót amit ma Lightning Networkként ismerünk. Az eseményt az Bitcoin Core fejlesztő csapat egyik prominens személye (Eric Lombrozo) az itt látható képpel
A GDAX-on néhány perce a Litecoin elérte a 98.3 USD árfolyamot és egyben bekarcolta a 0.02-es BTCLTC keresztet is, ami kétségtelenül annak köszönhető, hogy a Litecoin – mint a BTC produktív teszt környezete – ma bemutatta egy élő lightning network utalással azt, amiről évek óta szól a Bitcoin skálázási vita geek/technológiai oldalának propaganda gépezete. Az időközben “BsCore” gúnynévvel illetett Blocksteam és egyéb Bitcoin Core fejlesztőket tömörítő bagázs az elmúlt cca. egy évét arra tette fel, hogy létrehozza, implementálja és elfogadtassa azt a koncepciót amit ma Lightning Networkként ismerünk. Az eseményt az Bitcoin Core fejlesztő csapat egyik prominens személye (Eric Lombrozo) az itt látható képpel