Bár a hétvége eléggé borongósan kezdődött a szkeptikus várakozások okán, amit újra Jamie Dimon (JPMorgan vezér) borsozott meg azzal, hogy ismét megpróbálta (sikeresen…) leverni egy kicsit a Bitcoin árát. Látszik, hogy ez eféle nagyhalak is csak panelekben tudnak gondolkodni: Dimon odáig merészkedett, hogy kijelentette: Amennyiben a Bitcoin tovább erősödik és további erőforrásokat szippant ki a gazdaságból, akkor bizony nem marad más lehetősége a kormányoknak: úgy ahogy van be kell, hogy tiltsák az egész rendszert. Nice try… Idáig végső soron még Kína sem merészkedett el, az Oroszok meg egyenesen imádják Kreml szintig, majd persze, hogy pont a szabad világ választott vezetői fogják betiltani. Dimon szavaira tökéletesen igaz volt a mondás: “nagyobb a füstje, mint a lángja”. A crypto piaci hangulat már pémtek este óta látványosan kezd pozitívba fordulni. Ahelyett, hogy simán tételesen felsorolnám a pozitív történéseket engedjétek meg, hogy – saját elveimet követve – inkább a történések mögött meghúzódó várakozásokra koncentrálja.
Kezdjük talán egyből a technológiával. A héten a Litecoin fejlesztő csapata elemében volt. Teljesen váratlanul jelentették be egy éles Decred<->Litecoin atomic swap kísérletet, ami teljesen sikeres volt. Majd ezt követően péntek este Charlie Lee bejelentette, hogy végrehajtották az első BTC<->LTC atomic swapet is a mainneten. Mindezt nem sokkal azt követően, hogy szintén Charlie bejelentette az első sikeres LTC Lightning Network tranzakciót is, ami akkor majd 100 dollárig reppentette az LTC árfolyamát.
Miért is fontos ennyire az atomic swap? A blogon már többször is említettem a technológiát, azonban ezeddig nem nagyon volt szó ennek a gazdasági hatásáról. Az atomic swap gyakorlatilag ugyanazon elven működik, mint a Lightning Network: adott két fél, akik egymással two-of-two multi-sign contractot hoznak létre, amit speciális smart contractokon keresztül paramétereznek fel. Ezen paraméterek azt garantálják, hogy a felek úgy tudnak kicserélni két teljesen független blockláncon lévő két crypto pénzt, hogy egyik fél sem tud ezzel visszaélni, vagy menet közben lelépni. A módszer mögött meghúzódó technológia egy Tier Nolan pszeudonim fejlesztő nevéhez kapcsolódik. Részleteiben ebben a cikkben írtam erről. Alapvetően a Bitcoint és lényegében az összes relevánsabb cryptocurrencyt decentralizáltnak illetve peer-to-peernek terveztek. Azonban számos olyan szolgáltatás épült a peer-to-peer modellre, amelyek komoly centralizációt hoztak létre. Ennek egyik leglátványosabb példája a crypto tőzsde. Több olyan crypto tőzsde is létezik, ami konkrétan CSAK crypo-crypto tradinget nyújt szolgáltatásként. (pl. bittrex). Az atomic-swap részben szükségtelenné teszi a crypto tőzsdéket azáltal, hogy egy dencentralizált platformot nyújt a crypto valuták cseréjére. Nyilvánvaló, hogy az atomic-swap NEM tud helyettesíteni teljes körűleg egy tőzsdét, hiszen az ismeretlen felek közötti bizalmat a technológia azáltal biztosítja, hogy a kicserélendő coinök blockláncaiba publikálásra kerülnek a tranzakciók, így egy atomic-swap művelet átfutási idejét a tranzakció hitelesként való kezelését határozza meg (confirmation).
Ellenben az atomic-swap kölcsönös megegyezésen alapszik, ahol a tranzakció akár annak utolsó lépéséig megszakítható, így a tranzakciókban részt vevő felek lényegesen csökkenthetik a volatilitás adta kockázatot. A spekulatív ügyletek számára megmaradnak a tőzsdék, azonban a jövő Bitcoinra és egyéb crypto valutákra épülő vállalkozásai már nem kényszerülnek arra, hogy tőzsdéken, vagy akár olyan 3rd-party szolgáltatásokon keresztül cross-chain exchangeljenek mint amilyen pl a shapeshifter.io. Ráadásul az atomic-swap lényegesen fokozza a felek magánélethez való jogát is, hiszen az ilyen jellegű tranzakciók követése eléggé problémás a különböző blockláncokon keresztül. Hogy melyek azok az üzleti vállalkozások, akik éheznek az atomic swap adata lehetőségekre? Lényegében az összes crypto valuta ATM, bitcoin elfogadóhely, stb. Hiszen az atomic-swappen keresztül olyan hedging szolgáltatások is elérhetők lesznek hamarosan mint pl a BTC-USDT pár közötti swap.
Az atomic-swap által garantált decentralizálás egy további fontos előnye az arbitrázs intézményének visszaszorítása. Mivel atomic-swap esetén egyrészt adott a blockba foglalás, továbbá csak olyan felek között hozható létre akik rendelkeznek már egy multi-sign contracttal, ezért várhatóan főleg olyan felek között fog ez elterjedni, akik szándékosan szeretnének kimaradni a tőzsdék által generált volatilitásból, így egy atomic-swap contract hálózat esetén teljesen normális lehet, hogy a felek nem engedik be a zárt contract hálózatukba az arbitrázs tevékenységgel élőket, így sokkal jobban kiegyenlítődnek a volatilitás okozta hullámok. Mivel az ilyen kontraktusban várhatóan főleg olyan felek fognak részt venni, akik számára a napi cryptocoin forgalom elementális (lásd elfogadóhelyen, atm-ek, stb.), így ezen felek nem lesznek kénytelenek a likviditásukat a tőzsdékről pótolni, ami ezáltal a tőzsdéken is árfolyam stabilizálást és volatilitás csökkenést eredményezhet. Az AS-t (atomic-swap) egyfajta önszabályozó intézményként kell elképzelni, ahol a AS partnerek közötti hálózat ‘játékszabályai’ adják a self-regulation-t. Kvázi úgy kell ezt elképzelni, hogy az iszonyatosan volatilis pl. nyersanyag piacra épülő ETF-eket vagy befektetési alapokat, ahol a papír mögött ülő alapkezelő folyamatos stabilitásra törekszik.
Viszont mielőtt még bárki is megnyugodva ciccentene fel egy sört annak biztos tudatában, hogy: “végre megvan a crypto-volatilitás ellenszere”, had jegyezzem meg, hogy az AS és az LN adaptációja egy iszonyatosan lassú történet lesz. Példaként vehetjük a hasonló, de lényegesen kisebb technológiai hatású SegWitet: bő egy hónapja aktív a segwit és éppen most hétvégén érte végre el az adaptációja a 4%-ot azáltal, hogy végre újabb üzleti szereplők implementálták.
Na de történet itt a hétvégén más érdekesség is. James Altucher, tette közzé a hírt, hogy az Amazon bizony hamarosan (Október elején) hivatalosan is elfogadja fizetőeszközként a Bitcoint. A hírt Altucher szerint Scott Mullins (Amazon vezető) is megerősítette. A cég részéről ezeddig sem megerősítés, sem cáfolat nem született. Idén július 1-én írtam az alábbiakat itt a blogon: “A világ két legnagyobb gadget áruháza (AliExpress és Amazon) állítólag fej-fej mellett küzd azért, hogy implementálják a platformukon a bitcoin (és mellette a Litecoin) elfogadását fizetőeszközként. ” Ez az információ egy éppen akkor napvilágot látott Charlie Lee nyomán szárnyra kapott pletyka indukálta. Ami már akkor is biztos volt: Ahhoz, hogy egy Amazon szintű cég egyáltalán csak mérlegelje is a Bitcoin bevezetését, ahhoz két dolog biztosan kell: egy villámgyors második szintű fizetési rendszer (lightning network) és egy olyan felület, ahol a különböző crypto coinok között könnyedén lehet swappelni anélkül, hogy ki lennének a felek téve a tőzsdei problémáknak (robotok piacbefolyásolása, buywallok, lassulások, kimaradások, stb.). Ez a két funkció időközben elkészült, sőt ha úgy vesszük, akkor az elmúlt 3 hónapban Charlie csapatai szinte csak ezzel foglalkoztak. Technológiailag szinte minden adott immáron, hogy az Amazon meghozzon egy ilyen döntést. Márpedig az üzleti igény egyre nagyobb erre. India és Japán után több, az Amazon számára fontos régió, ország, nemzet is teret enged a Bitcoin másodlagos fizetőeszközként használatához. Nem alaptalan azt feltételezni, hogy egy Amazon sem szeretne ebből a buliból kimaradni.
Ami viszont fontos: amíg ezt a hírt NEM erősíti meg az Amazon addig az egész csak egy pletyka, ami simán lehet egy beteg árfolyam befolyásoló kísérlet is. Ahogy Jamie Dimon képes eladni magát a Bitcoin árának leveréséhez, úgy bármely más gazdasági szereplő (akár Altucher is) megteheti ugyanezt az ellenkező irány érdekében is. Persze az is tény, hogy Altucher mindösszesen csak egy üzleti szakértő, aki sikeres cégek garmadájával büszkélkedhet, szemben Dimonnal akinek a CV-jében többek között ott van a legutóbbi gazdasági világválság előidézése és azt követően a bankmentő csomag pofátlan felzabálása is. Szóval tény, hogy a két jóember nem egy kaliber.
Magam részéről nem nagyon adnék komoly esélyt annak, hogy valóban bevezetésre kerül a BTC/LTC az amazon piacán ennyire gyorsan. A közleményben Altucher egyébként lényegében azt fejti ki, hogy szerinte az AMAZON-nal nincs nagyon más választása mint implementálni a szuperpénzt és ezt erősítette meg számára az egyik prominensebb vezető is. Minden következtetés ezen túl már csak spekuláció. Szombaton este a piac ezt a spekulációt be is árazta, majd ma hajnalban szépen ki is árazta. Ilyen ez a popszakma.
Na de ha már az üzleti és befektetési köröket érintjük. Történt itt is érdekesség. Régóta húzzák halasztják már a Bitcoin (és Ethereum) mögöttes termékű ETF-ek bevezetését az amerikai tőzsdékre. Az ETF lényegében egy olyan befektetési alap, amely mögött adott termék, ötlet vagy iparág teljesítménye áll (esetünkben ugye BTC vagy akár ETH). Ahhoz, hogy egy ilyen ETF elkészülhessen előzetesen azt engedélyeztetni kell a SEC (tőzsdefelügyelet) intézményével, akik viszont ezeket az engedélyezés helyett igen sűrűn inkább visszadobálják pl. a volatilitásra és egyéb megfoghatatlan okokra hivatkozva. A héten két fontosabb ide tartozó hír is napvilágot látott:
- Egyrészt a LedgetX.com létrehozhat egy határidős bitcoin alapú szerződés formát (Prepaid Day-Ahead Bitcoin Swap), melyet várhatóan október 4-én fog tudni listázni.
- Az Evolve Funds beadta kezdeményezését Bitcoin alapú ETF kibocsátásra a kanadai tőzsdén (Torono Stock Exchange – TSX), mely már csak a helyi szabályozó (CSA) jóváhagyására vár. Az Evolve Funds már jelenleg is több igen kreatív ETF-et listáz a TSX-en, melyek miatt nagyon pozitív a piaci várakozás. Ha sikerül, akkor érdemes lesz megjegyezni a BITS tickert, hiszen ez lesz az ETF neve az TSX-en.
Hogy miért érdekes ez a két hír és hol kapcsolódik ez az U.S. ETF kérdéshez? A thestreet.com közölt le egy összefoglalót ETF témában. Jelenleg két csapat is küzd a ETF elsőbbségért az államokban. A bal sarokban jelenleg a The VanEck Vectors Bitcoin Strategy ETF áll, a jobb sarokban pedig a Winklevoss fivérek Bitcoin ETF-je. Az elmúlt fél évben leginkább az volt a kérdés, hogy VALAHA is lesz-e az államokban Bitcoin ETF. Mára ez a kérés inkább arról szól, hogy a két pályázó közül melyik kapja meg a jogosultságot előbb. A piaci várakozások szerint az ETF-ek indulása valamikor az év végére várható. A SEC pozitív döntése mellett szól az is, hogy a Stockholmi Nasdaq Nordic tőzsdén már bevezetett Bitcoin alapú ETN magas kereskedési volumen mellett stabilan tudja kiszolgálni a jellemzően amerikai nagybanki ügyfelek igényeit, akik ezen igényeiket minden sokkal szívesen végeznék otthon és gazdagítanák ezzel a helyi intézményeket. A Nasdaq Nordic XBT ETF-je napi átlag 20-60 millió USD-nyi forgalom mellett pörög, mely ilyen szempontból összemérhető számos nagyobb crypto tőzsde volumenével.




 Én leginkább ezt hoztam innen el, de lekerekítve mondókámat az alábbi képpel tudnám legjobban jelezni, hogy mit gondolok a jövőről:
Én leginkább ezt hoztam innen el, de lekerekítve mondókámat az alábbi képpel tudnám legjobban jelezni, hogy mit gondolok a jövőről:

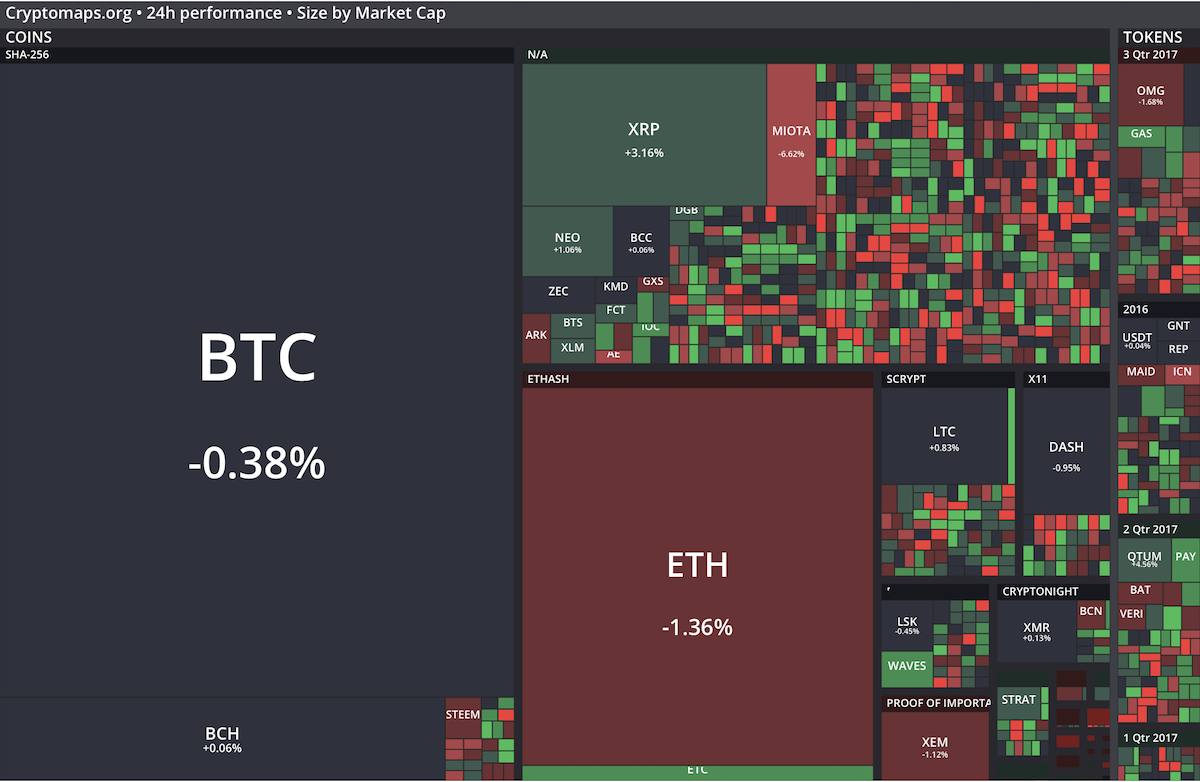
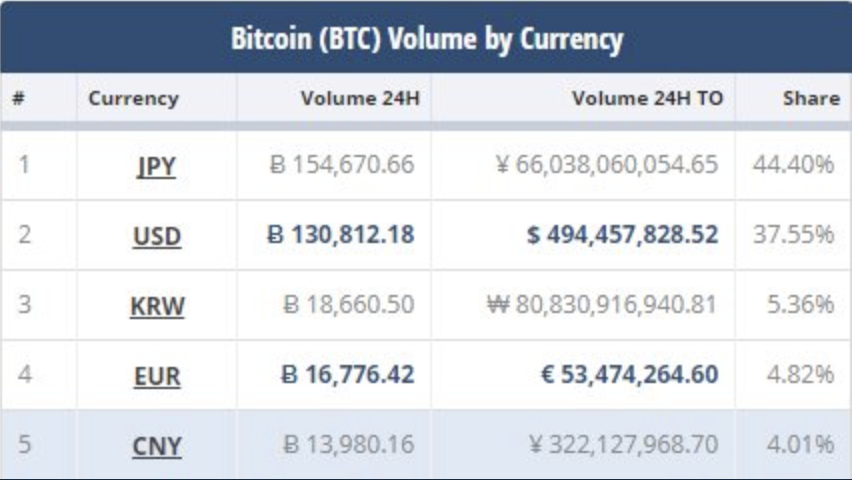 A tegnapi nappal az összes kínai tőzsde napi forgalma kikerült a top10-es listából. Helyükre a japán yen és a koreai won kereszt árfolyamok kerültek be. Ebből is látszik, hogy a pénz szépen lassan elkezdett mozogni a liberálisabb felfogású országok irányába.
A tegnapi nappal az összes kínai tőzsde napi forgalma kikerült a top10-es listából. Helyükre a japán yen és a koreai won kereszt árfolyamok kerültek be. Ebből is látszik, hogy a pénz szépen lassan elkezdett mozogni a liberálisabb felfogású országok irányába. Persze nem csak Kínáról szól a világ. Itt vannak az Orosz testvéreink is:
Persze nem csak Kínáról szól a világ. Itt vannak az Orosz testvéreink is: