Követve a hazai és nemzetközi közösségi oldalakat nap mint nap szembesülök azzal, hogy mennyire nincs meg még a minimális pénzügyi előképzettsége se azoknak, akik nem csak, hogy beleugranak #HODL-ként a crypto világba, de egyből aktívan neki is fognak kereskedni a tőzsdéken. Ha nem tudod, hogy mi az a limit áras megbízás, nem használsz trailing stop ordert és a conditional close opció sem mond nagyon semmit, akkor ez a post neked készült, ne riasszon el a végig olvasásástól az a tény, hogy esetleg sértőn hathat rád a bevezető általánosítása.
Szóval tisztelet persze a kivételnek, de azt látni kell, hogy a fent megnevezett emberek igen komolyan hozzájárulnak a crypto valuták volatilitásához. Hogy mennyire? Nézzünk egy példát:
- Nagy para hangulatot okozott nálam 2 napja, amikor először megérintette a bitcoin árfolyam a 4000 usa dollárt. Akkor az árfolyam hirtelen visszakorrigált 3700 dollárig, ahonnan persze igen hamar recoveryzett újra a 4000-es tartományba, ahol azóta is látványosan jól érzi magát.
- Kellett némi idő akkor, hogy realizáljam: nincs itt semmi látnivaló, valójában csak tele volt pakolva az összes tőzsde take profit orderekkel amit a szép kerek 4000 dolláros küszöbértéken aktivizálódtak. Nem hiába, az emberek szeretik a kerek számokat. (Pedig a π mennyivel egy menőbb szám már!)
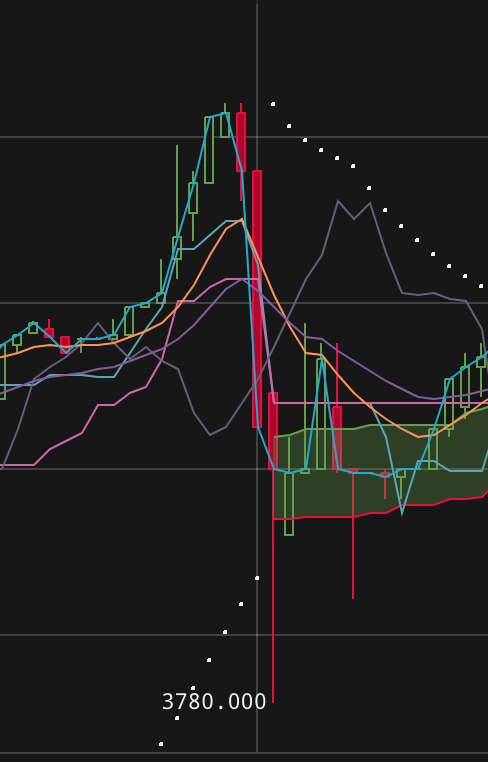 Hogy mi is történt pontosan 2017.08.12 18:57 és 19:03 között? Az árfolyam elérve a 4000 dollárt, aktivált egy halom ‘take profit – market price’ megbízást. Egészen pontosan ebben a kb. 6 percben 269 BTC-nyi eladás történt a kraken.com-on, amiből 218 btc marketprice-on lett rögzítve! Valójában persze a kraken-en nem érte el az árfolyam a 4000 USD-t, ellenben a coinbasen igen, aminek határása az arbitrage robotok elkezték aktiválni az automatikus ordereiket mindenhol. Így bár a konkrét esetben a kraken-en éppen nem aktiválódtak a bután berakott take profit orderek, de a történet szempontjából a továbbiakban kezeljük úgy, hogy mégis. (Lusta vagyok a cikkhez készített scriptet átportolni a coinbase API-jára…)
Hogy mi is történt pontosan 2017.08.12 18:57 és 19:03 között? Az árfolyam elérve a 4000 dollárt, aktivált egy halom ‘take profit – market price’ megbízást. Egészen pontosan ebben a kb. 6 percben 269 BTC-nyi eladás történt a kraken.com-on, amiből 218 btc marketprice-on lett rögzítve! Valójában persze a kraken-en nem érte el az árfolyam a 4000 USD-t, ellenben a coinbasen igen, aminek határása az arbitrage robotok elkezték aktiválni az automatikus ordereiket mindenhol. Így bár a konkrét esetben a kraken-en éppen nem aktiválódtak a bután berakott take profit orderek, de a történet szempontjából a továbbiakban kezeljük úgy, hogy mégis. (Lusta vagyok a cikkhez készített scriptet átportolni a coinbase API-jára…)
Ezzel a mennyiséggel gyakorlatilag sikerült kinullázni az orderbook ‘ask’ oldalát alig 4-5 perc alatt, ezzel az árfolyamot lelökni 300 dollárral mínuszba. Ha 2x ennyi take profit megbízás lett volna, akkor az árfolyam akár 3000 dollár alá is be tudott volna zuhanni, annyira kevés ask megbízás volt már ebben a pillanatban az orderbookban. Emlékezetes a június középén bekövetkezett GDAX Ethereum crash, akkor is gyakorlatilag annyi történt, hogy beindult egy stoploss bomba, ami az egyébként 300 dollár feletti Ethereum árfolyamát egészen 1 dollár alá vitte le. Mindezt csak azért, mert a stop lossok nagy része piaci áras megbízás volt.
Folytatás…





 Olvasgatva a
Olvasgatva a  Petya haverom (akinek aranyköpéseit korábban már számos esetben osztottam meg veletek a blogon), abbéli döntésre jutott, hogy akkor ő innentől sz*rik a farmkra és nem bányászik tovább. Helyette a pénzét inkább gázhajtású hangyafarmokba öli, hiszen abban van most a nagy della. Ha már egyszer ő a variance.hu blog sokat rejtegetett celebe, akkor gondolta kihasználja eme népszerűséget, hogy a blog hasábjain próbáljon új gazdát találni két alig használni 5 GPUs miner rigének. A két RIG egy darab cipősszekrénybe van szerelve, tehát a büszke új tulajdonos vagy megveszi egyben mindkét rig-et, vagy a kettő közül az egyik keret nélkül oldható csak meg.
Petya haverom (akinek aranyköpéseit korábban már számos esetben osztottam meg veletek a blogon), abbéli döntésre jutott, hogy akkor ő innentől sz*rik a farmkra és nem bányászik tovább. Helyette a pénzét inkább gázhajtású hangyafarmokba öli, hiszen abban van most a nagy della. Ha már egyszer ő a variance.hu blog sokat rejtegetett celebe, akkor gondolta kihasználja eme népszerűséget, hogy a blog hasábjain próbáljon új gazdát találni két alig használni 5 GPUs miner rigének. A két RIG egy darab cipősszekrénybe van szerelve, tehát a büszke új tulajdonos vagy megveszi egyben mindkét rig-et, vagy a kettő közül az egyik keret nélkül oldható csak meg.
